



Para los expertos en SEO, las actualizaciones principales de Google son una forma de vida. Sucederán al menos una vez, si no varias veces, al año.
Naturalmente, habrá ganadores y perdedores.
Entonces, aunque Google no revela la mayoría de los factores de clasificación detrás de las actualizaciones del algoritmo, hay cosas que podemos hacer para obtener una mayor comprensión de lo que está pasando, en términos de:
- Qué contenido del sitio se ve afectado.
- Sitios que operan en su espacio de búsqueda.
- Tipos de resultados.
El límite es tu imaginación, tus preguntas (basadas en tus conocimientos de SEO) y, por supuesto, tus datos.
Este código cubrirá las agregaciones en el nivel de la página de resultados del motor de búsqueda (SERP) (comparación de categorías entre sitios), y los mismos principios se pueden aplicar a otras vistas de la actualización principal, como los tipos de resultados (piense fragmentos y otras opiniones mencionadas anteriormente).
Usar Python para comparar SERP
El principio general es comparar los SERP antes y después de la actualización principal, lo que nos dará algunas pistas sobre lo que está pasando.
Comenzaremos importando nuestras bibliotecas de Python:
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inline
Al definir algunas variables, nos centraremos en ON24.com, ya que perdieron en la actualización principal.
root_domain = 'on24.com' hostdomain = 'www.on24.com' hostname="on24" full_domain = 'https://www.on24.com' site_name="ON24"
Al leer los datos, estamos usando una exportación de GetSTAT que tiene un informe útil que le permite comparar los SERP de sus palabras clave antes y después.
Este informe de SERP está disponible en otros proveedores de seguimiento de clasificación como Monitoreo de SEO y Clasificación web avanzada – ¡Sin preferencias ni avales de mi parte!
getstat_ba_urls = pd.read_csv('data/webinars_top_20.csv', encoding = 'UTF-16', sep = 't')
getstat_raw.head()

getstat_ba_urls = getstat_raw
Construya las URL uniendo el protocolo y la cadena de URL para obtener la URL de clasificación completa antes y después de la actualización.
getstat_ba_urls['before_url'] = getstat_ba_urls['Protocol for Nov 19, 2020'] + '://' + getstat_ba_urls['Ranking URL on Nov 19, 2020'] getstat_ba_urls['after_url'] = getstat_ba_urls['Protocol for Dec 17, 2020'] + '://' + getstat_ba_urls['Ranking URL on Dec 17, 2020'] getstat_ba_urls['before_url'] = np.where(getstat_ba_urls['before_url'].isnull(), '', getstat_ba_urls['before_url']) getstat_ba_urls['after_url'] = np.where(getstat_ba_urls['after_url'].isnull(), '', getstat_ba_urls['after_url'])
Para obtener los dominios de las URL de clasificación, creamos una copia de la URL en una nueva columna, eliminamos los subdominios usando una declaración if incrustada en una lista de comprensión:
getstat_ba_urls['before_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['before_url']]
stop_sites = ['hub.', 'blog.', 'www.', 'impact.', 'harvard.', 'its.', 'is.', 'support.']
getstat_ba_urls['before_site'] = getstat_ba_urls['before_site'].str.replace('|'.join(stop_sites), '')
La comprensión de la lista se repite para extraer la actualización posterior de los dominios.
getstat_ba_urls['after_site'] = [uritools.urisplit(x).authority if uritools.isuri(x) else x for x in getstat_ba_urls['after_url']]
getstat_ba_urls['after_site'] = getstat_ba_urls['after_site'].str.replace('|'.join(stop_sites), '')
getstat_ba_urls.columns = [x.lower() for x in getstat_ba_urls.columns]
getstat_ba_urls = getstat_ba_urls.rename(columns = {'global monthly search volume': 'search_volume'
})
getstat_ba_urls
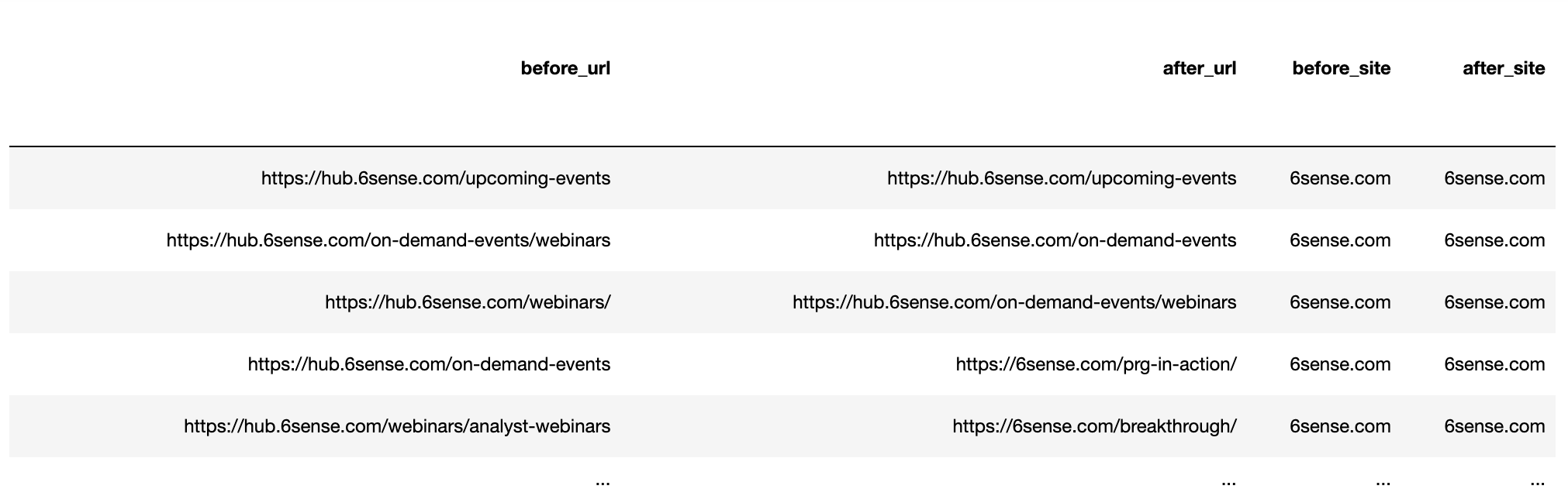 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Deduplicación de varias URL de clasificación
El siguiente paso es eliminar las URL de clasificación múltiple por el mismo dominio por palabra clave SERP. Dividiremos los datos en dos conjuntos, antes y después.
Luego, agruparemos por palabra clave y realizaremos la deduplicación:
getstat_bef_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for nov 19, 2020', 'protocol for nov 19, 2020',
'ranking url on nov 19, 2020', 'before_url', 'before_site']]
getstat_bef_unique = getstat_bef_unique.sort_values('rank').groupby(['before_site', 'device', 'keyword']).first()
getstat_bef_unique = getstat_bef_unique.reset_index()
getstat_bef_unique = getstat_bef_unique[getstat_bef_unique['before_site'] != '']
getstat_bef_unique = getstat_bef_unique.sort_values(['keyword', 'device', 'rank'])
getstat_bef_unique = getstat_bef_unique.rename(columns = {'rank': 'before_rank',
'result types for nov 19, 2020': 'before_snippets'})
getstat_bef_unique = getstat_bef_unique[['keyword', 'market', 'device', 'before_snippets', 'search_volume',
'before_url', 'before_site', 'before_rank'
]]
getstat_bef_unique
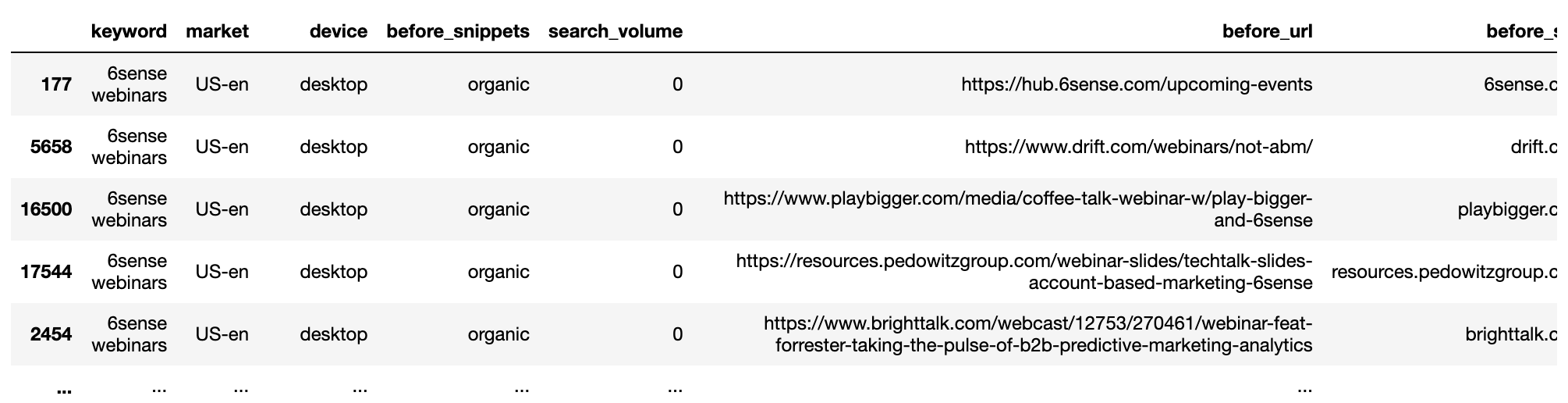 Captura de pantalla del autor, enero de 2022
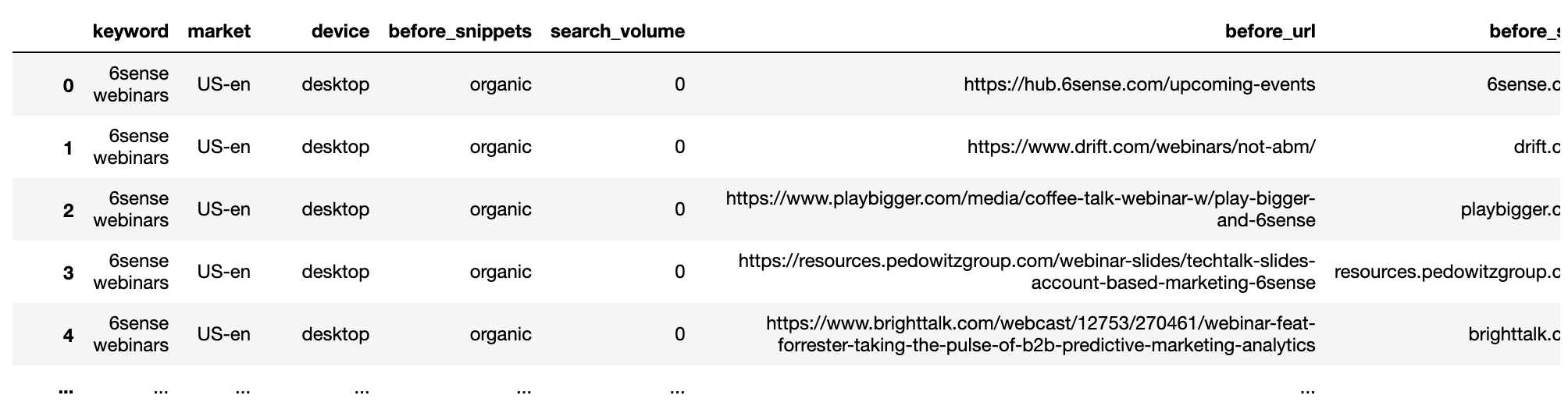
Captura de pantalla del autor, enero de 2022El procedimiento se repite para el conjunto de datos posteriores.
getstat_aft_unique = getstat_ba_urls[['keyword', 'market', 'location', 'device', 'search_volume', 'rank',
'result types for dec 17, 2020', 'protocol for dec 17, 2020',
'ranking url on dec 17, 2020', 'after_url', 'after_site']]
getstat_aft_unique = getstat_aft_unique.sort_values('rank').groupby(['after_site', 'device', 'keyword']).first()
getstat_aft_unique = getstat_aft_unique.reset_index()
getstat_aft_unique = getstat_aft_unique[getstat_aft_unique['after_site'] != '']
getstat_aft_unique = getstat_aft_unique.sort_values(['keyword', 'device', 'rank'])
getstat_aft_unique = getstat_aft_unique.rename(columns = {'rank': 'after_rank',
'result types for dec 17, 2020': 'after_snippets'})
getstat_aft_unique = getstat_aft_unique[['keyword', 'market', 'device', 'after_snippets', 'search_volume',
'after_url', 'after_site', 'after_rank'
]]
Segmentar los sitios SERP
Cuando se trata de actualizaciones principales, la mayoría de las respuestas tienden a estar en los SERP. Aquí es donde podemos ver qué sitios están siendo premiados y otros que salen perdiendo.
Con los conjuntos de datos deduplicados y separados, determinaremos los competidores comunes para poder comenzar a segmentarlos manualmente, lo que nos ayudará a visualizar el impacto de la actualización.
serps_before = getstat_bef_unique serps_after = getstat_aft_unique serps_before_after = serps_before_after.merge(serps_after, left_on = ['keyword', 'before_site', 'device', 'market', 'search_volume'], right_on = ['keyword', 'after_site', 'device', 'market', 'search_volume'], how = 'left')
Limpiar las columnas de clasificación de valores nulos (NAN no es un número) utilizando la función np.where(), que es el equivalente de Panda a la fórmula if de Excel.
serps_before_after['before_rank'] = np.where(serps_before_after['before_rank'].isnull(), 100, serps_before_after['before_rank']) serps_before_after['after_rank'] = np.where(serps_before_after['after_rank'].isnull(), 100, serps_before_after['after_rank'])
Algunas métricas calculadas para mostrar la diferencia de clasificación antes y después, y si la URL cambió.
serps_before_after['rank_diff'] = serps_before_after['before_rank'] - serps_before_after['after_rank'] serps_before_after['url_change'] = np.where(serps_before_after['before_url'] == serps_before_after['after_url'], 0, 1) serps_before_after['project'] = site_name serps_before_after['reach'] = 1 serps_before_after
 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Agregue los sitios ganadores
Con los datos limpios, ahora podemos agregarlos para ver qué sitios son los más dominantes.
Para hacer esto, definimos la función que calcula el rango promedio ponderado por volumen de búsqueda.
No todas las palabras clave son tan importantes, lo que ayuda a que el análisis sea más significativo si le importan las palabras clave que obtienen la mayoría de las búsquedas.
def wavg_rank(x):
names = {'wavg_rank': (x['before_rank'] * (x['search_volume'] + 0.1)).sum()/(x['search_volume'] + 0.1).sum()}
return pd.Series(names, index=['wavg_rank']).round(1)
rank_df = serps_before_after.groupby('before_site').apply(wavg_rank).reset_index()
reach_df = serps_before_after.groupby('before_site').agg({'reach': 'sum'}).sort_values('reach', ascending = False).reset_index()
commonstats_full_df = rank_df.merge(reach_df, on = 'before_site', how = 'left').sort_values('reach', ascending = False)
commonstats_df = commonstats_full_df.sort_values('reach', ascending = False).reset_index()
commonstats_df.head()
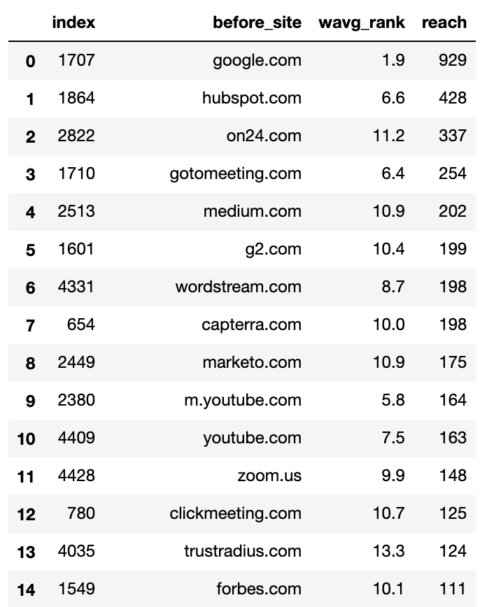 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Si bien el rango promedio ponderado es importante, también lo es el alcance, ya que nos indica la amplitud de la presencia del sitio en Google, es decir, la cantidad de palabras clave.
El alcance también nos ayuda a priorizar los sitios que queremos incluir en nuestra segmentación.
La segmentación funciona mediante el uso de la función np.select, que es como una fórmula if mega anidada de Excel.
Primero, creamos una lista de nuestras condiciones.
domain_conds = [ commonstats_df['before_site'].isin(['google.com', 'medium.com', 'forbes.com', 'en.m.wikipedia.org', 'hbr.org', 'en.wikipedia.org', 'smartinsights.com', 'mckinsey.com', 'techradar.com','searchenginejournal.com', 'cmswire.com']), commonstats_df['before_site'].isin(['on24.com', 'gotomeeting.com', 'marketo.com', 'zoom.us', 'livestorm.co', 'hubspot.com', 'drift.com', 'salesforce.com', 'clickmeeting.com', 'qualtrics.com', 'workcast.com', 'livewebinar.com', 'getresponse.com', 'superoffice.com', 'myownconference.com', 'info.workcast.com']), commonstats_df['before_site'].isin([ 'neilpatel.com', 'ventureharbour.com', 'wordstream.com', 'business.tutsplus.com', 'convinceandconvert.com']), commonstats_df['before_site'].isin(['trustradius.com', 'g2.com', 'capterra.com', 'softwareadvice.com', 'learn.g2.com']), commonstats_df['before_site'].isin(['youtube.com', 'm.youtube.com', 'facebook.com', 'linkedin.com', 'business.linkedin.com', ]) ]
Luego creamos una lista de los valores que queremos asignar para cada condición.
segment_values = ['publisher', 'martech', 'consulting', 'reviews', 'social_media']
Luego crea una nueva columna y usa np.select para asignarle valores usando nuestras listas como argumentos.
commonstats_df['segment'] = np.select(domain_conds, segment_values, default="other") commonstats_df = commonstats_df[['before_site', 'segment', 'reach', 'wavg_rank']] commonstats_df
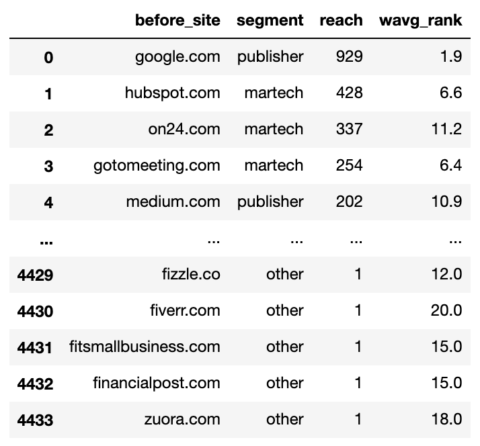 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Los dominios ahora están segmentados, lo que significa que podemos comenzar la diversión de agregar para ver qué tipos de sitios beneficiados y deteriorados por la actualización.
# SERPs Before and After Rank serps_stats = commonstats_df[['before_site', 'segment']] serps_segments = commonstats_df.segment.to_list()
Estamos uniendo los datos SERP anteriores únicos con la tabla de segmentos SERP creada inmediatamente arriba para segmentar las URL de clasificación usando la función de combinación.
La función de combinación que usa el parámetro ‘eft’ es equivalente a la función de búsqueda de Excel o de coincidencia de índice.
serps_before_segmented = getstat_bef_unique.merge(serps_stats, on = 'before_site', how = 'left') serps_before_segmented = serps_before_segmented[~serps_before_segmented.segment.isnull()] serps_before_segmented = serps_before_segmented[['keyword', 'segment', 'device', 'search_volume', 'before_snippets', 'before_rank', 'before_url', 'before_site']] serps_before_segmented['count'] = 1 serps_queries = serps_before_segmented['keyword'].to_list() serps_queries = list(set(serps_queries)) serps_before_segmented
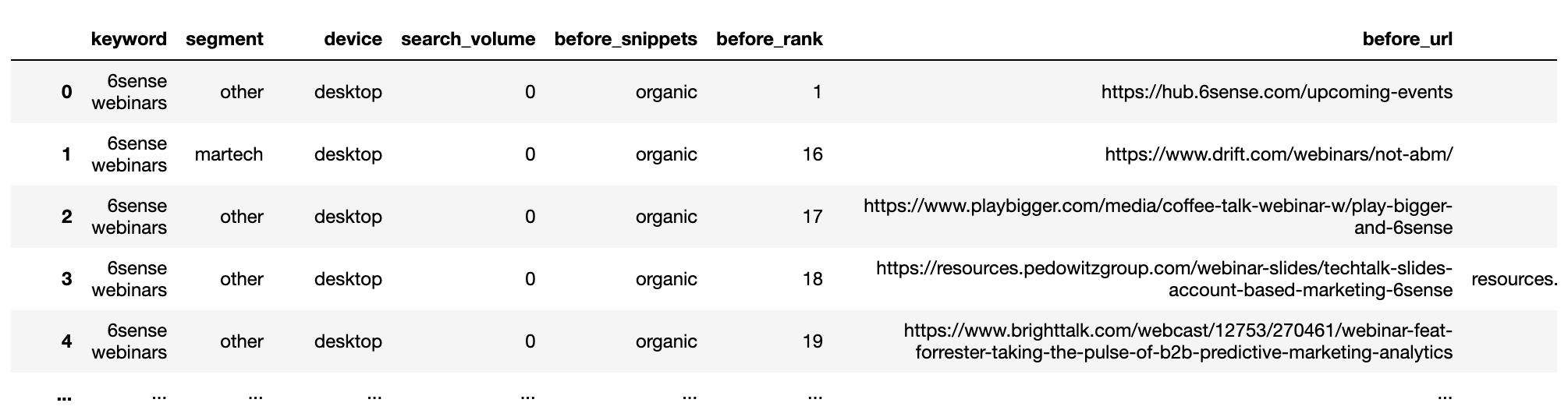 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Agregando los SERP anteriores:
def wavg_rank_before(x):
names = {'wavg_rank_before': (x['before_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_before']).round(1)
serps_before_agg = serps_before_segmented
serps_before_wavg = serps_before_agg.groupby(['segment', 'device']).apply(wavg_rank_before).reset_index()
serps_before_sum = serps_before_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_before_stats = serps_before_wavg.merge(serps_before_sum, on = ['segment', 'device'], how = 'left')
serps_before_stats = serps_before_stats.rename(columns = {'count': 'before_n'})
serps_before_stats
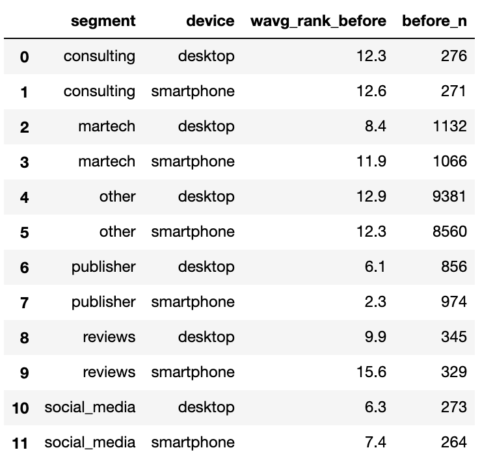 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Repita el procedimiento para las SERP posteriores.
# SERPs After Rank
aft_serps_segments = commonstats_df[['before_site', 'segment']]
aft_serps_segments = aft_serps_segments.rename(columns = {'before_site': 'after_site'})
serps_after_segmented = getstat_aft_unique.merge(aft_serps_segments, on = 'after_site', how = 'left')
serps_after_segmented = serps_after_segmented[~serps_after_segmented.segment.isnull()]
serps_after_segmented = serps_after_segmented[['keyword', 'segment', 'device', 'search_volume', 'after_snippets',
'after_rank', 'after_url', 'after_site']]
serps_after_segmented['count'] = 1
serps_queries = serps_after_segmented['keyword'].to_list()
serps_queries = list(set(serps_queries))
def wavg_rank_after(x):
names = {'wavg_rank_after': (x['after_rank'] * x['search_volume']).sum()/(x['search_volume']).sum()}
return pd.Series(names, index=['wavg_rank_after']).round(1)
serps_after_agg = serps_after_segmented
serps_after_wavg = serps_after_agg.groupby(['segment', 'device']).apply(wavg_rank_after).reset_index()
serps_after_sum = serps_after_agg.groupby(['segment', 'device']).agg({'count': 'sum'}).reset_index()
serps_after_stats = serps_after_wavg.merge(serps_after_sum, on = ['segment', 'device'], how = 'left')
serps_after_stats = serps_after_stats.rename(columns = {'count': 'after_n'})
serps_after_stats
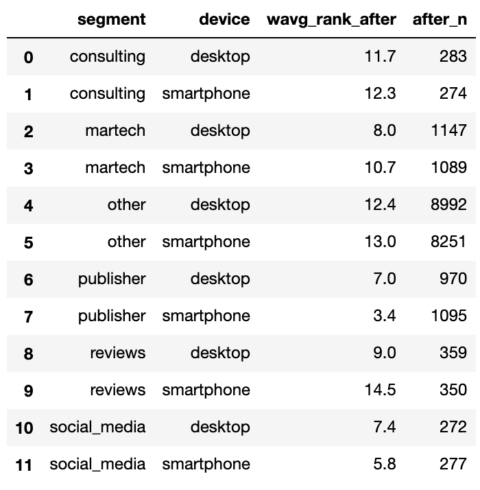 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Con ambos SERP resumidos, podemos unirlos y comenzar a hacer comparaciones.
serps_compare_stats = serps_before_stats.merge(serps_after_stats, on = ['device', 'segment'], how = 'left') serps_compare_stats['wavg_rank_delta'] = serps_compare_stats['wavg_rank_after'] - serps_compare_stats['wavg_rank_before'] serps_compare_stats['sites_delta'] = serps_compare_stats['after_n'] - serps_compare_stats['before_n'] serps_compare_stats
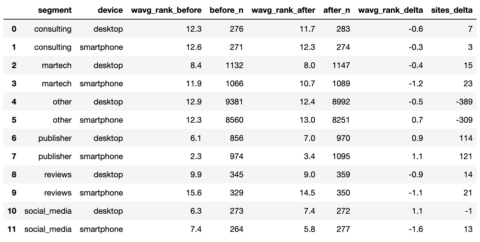 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Aunque podemos ver que los sitios de los editores parecían ganar más en virtud de más palabras clave clasificadas, una imagen seguramente diría 1000 palabras más en una presentación de PowerPoint.
Nos esforzaremos por hacer esto remodelando los datos en un formato largo que favorece el paquete de gráficos de Python ‘plotnine’.
serps_compare_viz = serps_compare_stats
serps_rank_viz = serps_compare_viz[['device', 'segment', 'wavg_rank_before', 'wavg_rank_after']].reset_index()
serps_rank_viz = serps_rank_viz.rename(columns = {'wavg_rank_before': 'before', 'wavg_rank_after': 'after', })
serps_rank_viz = pd.melt(serps_rank_viz, id_vars=['device', 'segment'], value_vars=['before', 'after'],
var_name="phase", value_name="rank")
serps_rank_viz
serps_ba_plt = (
ggplot(serps_rank_viz, aes(x = 'segment', y = 'rank', colour="phase",
fill="phase")) +
geom_bar(stat="identity", alpha = 0.8, position = 'dodge') +
labs(y = 'Google Rank', x = 'phase') +
scale_y_reverse() +
theme(legend_position = 'right', axis_text_x=element_text(rotation=90, hjust=1)) +
facet_wrap('device')
)
serps_ba_plt
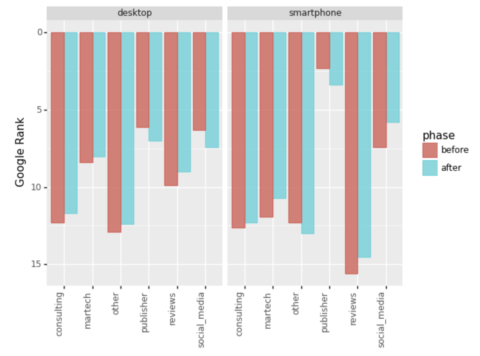 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Y tenemos nuestra primera visualización, que nos muestra cómo la mayoría de los tipos de sitios ganaron en el ranking, que es solo la mitad de la historia.
Veamos también el número de entradas en el top 20.
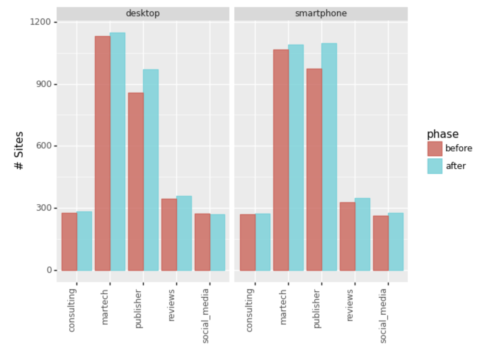 Captura de pantalla del autor, enero de 2022
Captura de pantalla del autor, enero de 2022Ignorando el segmento ‘Otro’, podemos ver que Martech y Publishers fueron los principales ganadores al expandir el alcance de sus palabras clave.
Resumen
Se necesitó un poco de código para crear un solo gráfico con toda la limpieza y agregación.
Sin embargo, los principios se pueden aplicar para lograr puntos de vista extendidos de ganador-perdedor, tales como:
- Nivel de dominio.
- Contenido interno del sitio.
- Tipos de resultados.
- Resultados canibalizados.
- Tipos de contenido de URL de clasificación (blogs, páginas de ofertas, etc.).
La mayoría de los informes SERP tendrán los datos para realizar las vistas extendidas anteriores.
Si bien es posible que no revele explícitamente el factor de clasificación clave, las vistas pueden decirle mucho sobre lo que está sucediendo, ayudarlo a explicar la actualización principal a sus colegas y generar hipótesis para probar si es uno de los menos afortunados buscando para recuperar.
Más recursos:
Imagen destacada: Cazador de píxeles/Shutterstock

«Food ninja. Freelance pop culture fanatic. Wannabe zombie maven. Twitter aficionado.»
More Stories
La red social Butterflies AI añade una función que te convierte en un personaje de inteligencia artificial
Edición del vigésimo aniversario de Hautlence HLXX: redefiniendo el tiempo con minutos que retroceden y horas saltantes
Un marco para resolver ecuaciones diferenciales parciales equivalentes puede guiar el procesamiento y la ingeniería de gráficos por computadora